

This article presents the core concepts behind a well-designed system. I will focus on distributed web services, as they are the most present systems nowadays. As before, the concepts can be used for any other kind of software system.
Goals of a Distributed System
A distributed system aims to maximize availability, reliability and performance through well-known concepts that you will need to consider while designing a system. For a start, let’s define those goals:
Availability: The capacity of your system to keep working at any time, even if something goes wrong.
Reliability: The capacity for things to not go wrong on your system during a long period of time.
Performance: The capacity of your system to work quickly and efficiently.
As you may have noticed, there is a correlation between reliability and availability, but the concepts should not be confused. A system with poor availability will probably be unreliable, but an unreliable system can sometimes remain available given enough resources.
Availability
In order to keep a system available, the main concept to keep in mind is redundancy. In a perfect world, everything in your system should be duplicated in order to palliate a dysfunction. Fortunately, thanks to the abstraction of computer science, you will be able to rely on the availability of the underlying systems you use, namely for cloud environments.
On your side of the system, availability will be mainly driven by using load balancing in front of your services, and replication for your databases.
The load balancing will redirect calls directed towards any service to a reliably working instance. This keeps your service responding even if a few instances are down. It also optimizes the load received by each instance, hence can impact positively the performances of your services. The load balancer is a component of our system, and as such we also need to create multiple instances of it.
Replication on a database system intends to keep your data safe from system failure, and also improve access capabilities through load balancing. Depending on the data criticality, you may also consider replicating your data on multiple physical locations. This is becoming easier thanks to cloud providers and can be very helpful.
Reliability
Reliability won’t necessarily be represented by actual components. However, there are some actionable that can help to ensure the production of a reliable system.
For service to remain reliable in the long run, it should be maintainable. Maintainability comes with clean code and a sensible codebase size. A service doing too many things will cost a lot to scale and may become cumbersome to maintain. While services too atomic will add complexity to your deployments and debugging processes. Uber published a good article on the advantages of finding the right sizing.
Performances
One of the advantages of a distributed is to ease the horizontal scaling, i.e. adding more instances of a service to serve more requests. This means that your services can evolve independently depending on their load.
Having said that, scaling is a costly solution, and even if it can help for short-term spikes, you may want to try optimizing before resorting to it in the long run. If you intend to send a lot of times the same data, the main way of improving your performance will be through using a Cache.
A Cache is basically storing the results of a request, and sending this result to any further request that matches, until invalidation. It will be your main ally to reduce loads over services and databases but may be counterproductive for queries that are requiring live data, as you want to see the changes and not be locked on a snapshot. A good example of a cached system is a Content Delivery Network (CDN), which is widely used to deliver static content as fast as possible.
The performance of a single component becomes more and more important with the number of dependencies others have on it. A component that becomes central in your architecture is named a Single Point Of Failure (SPOF). A SPOF will slow or bring down all your system if it has performance issues. You may want to avoid those as much as possible, but if that is a requirement of your systems, take extra care of the performance and availability of this component.
Distributed System Template
In order to apply the three concepts above, the main course of action is to almost always have at least two instances of each component. You may also need to push it further by having instances of each component in at least two geographical regions.
To be able to do so, your software should be stateless as much as possible, having a state will significantly increase the complexity of replicating components across multiple instances of regions.
The following schema represents a template of a system designed to be available, reliable, and performant.
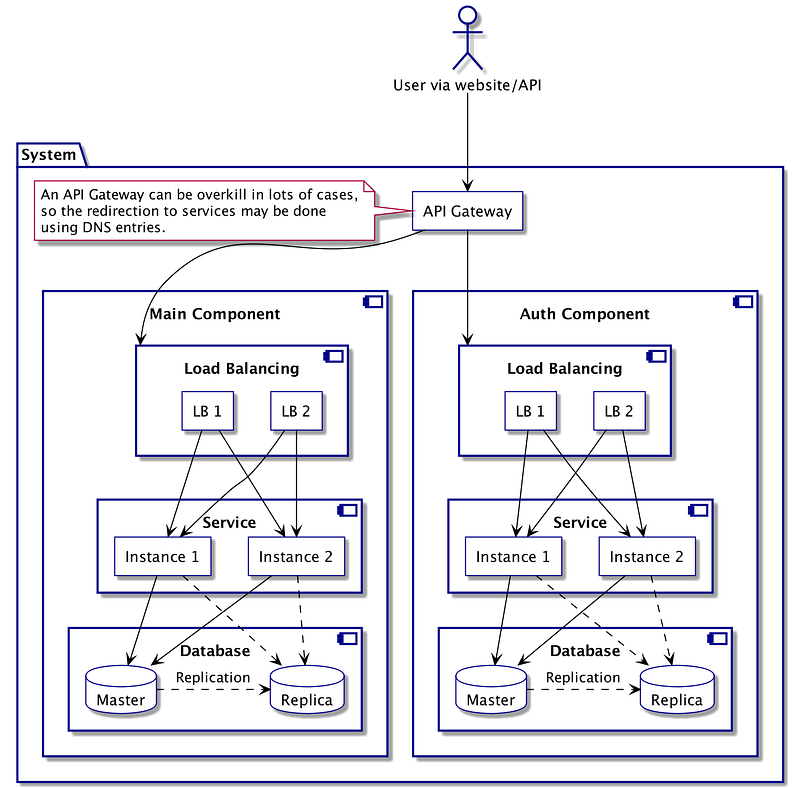 Detailed Typical Distributed System ArchitectureIn this design, the API Gateway have the advantage of providing a single, standardized, entry point on both sides of communications. For instance, you can use the gateway to provide an authentication layer on every incoming request, making it easier for services to handle authorization levels. On the other hand, you may have recognized a SPOF in this component. If the gateway goes down, your entire infrastructure will be unavailable, making the component critical in regard to code quality and performance.
Detailed Typical Distributed System ArchitectureIn this design, the API Gateway have the advantage of providing a single, standardized, entry point on both sides of communications. For instance, you can use the gateway to provide an authentication layer on every incoming request, making it easier for services to handle authorization levels. On the other hand, you may have recognized a SPOF in this component. If the gateway goes down, your entire infrastructure will be unavailable, making the component critical in regard to code quality and performance.
Ensure That The Goals Are Reached
In order to ensure that your system is indeed up to standard, you will need to monitor its behaviour in real time. Hopefully, a lot of tools exist to do so, exporting metrics, logs, and traces from your software and underlying systems. Depending on your needs, you can rely on open-source software like Prometheus & Grafana, or enterprise solutions like Datadog.
Having a well-designed observability stack above your systems will help you pin down issues with more ease, thus greatly improving your response time in case of any issue on your system.
Conclusion
There is no silver bullet in system design. However, it can be helpful to have a template in mind whenever designing a new system. This will help efficiently create something relevant with only a few tweaks depending on the requirements of your system.
As I said before, this template design is highly personal and may vary.
Now that we defined the coarse-grained design, let’s discuss the details. First, we will see how to do some back-of-the-envelope calculations to scale correctly.